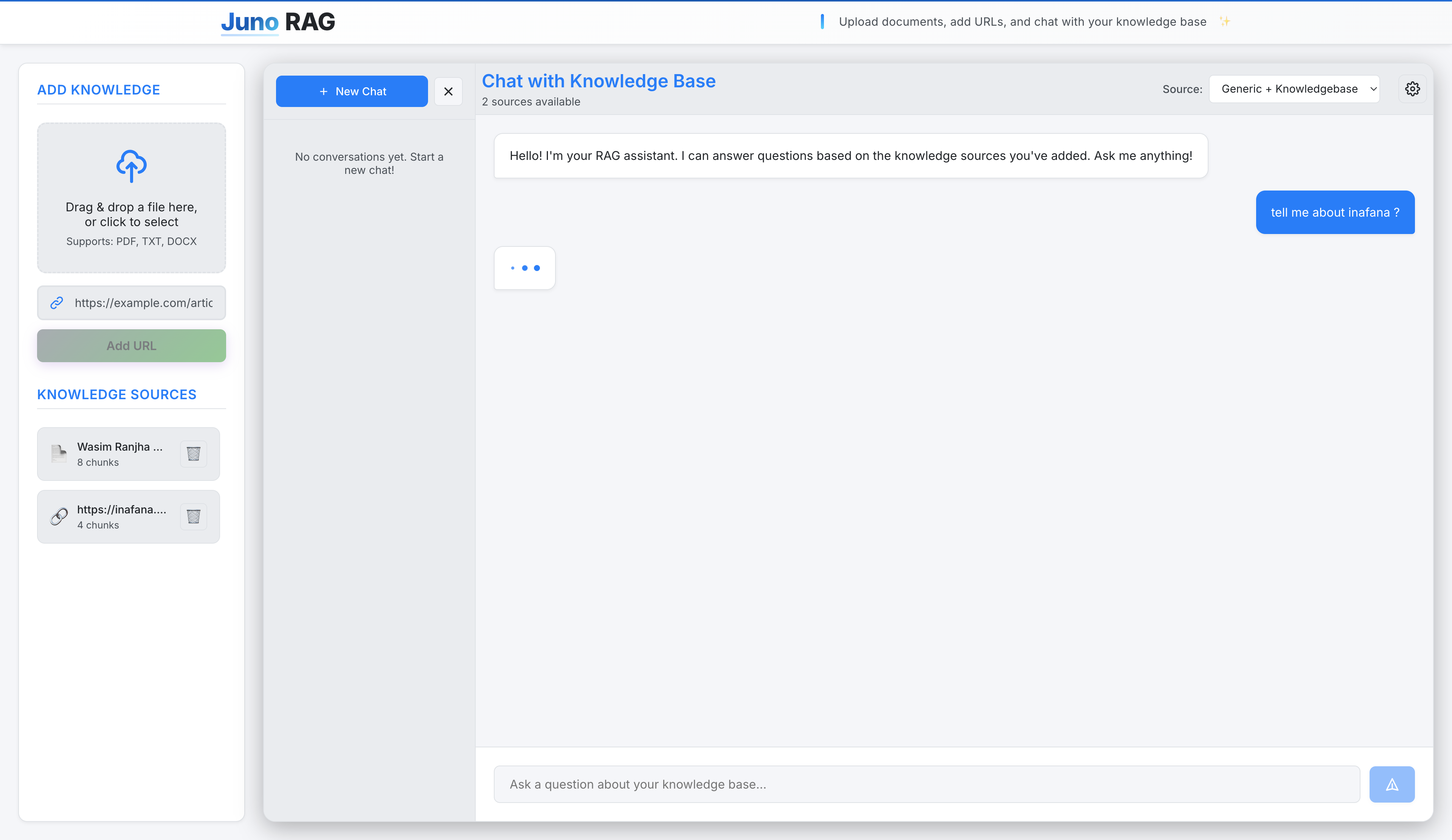
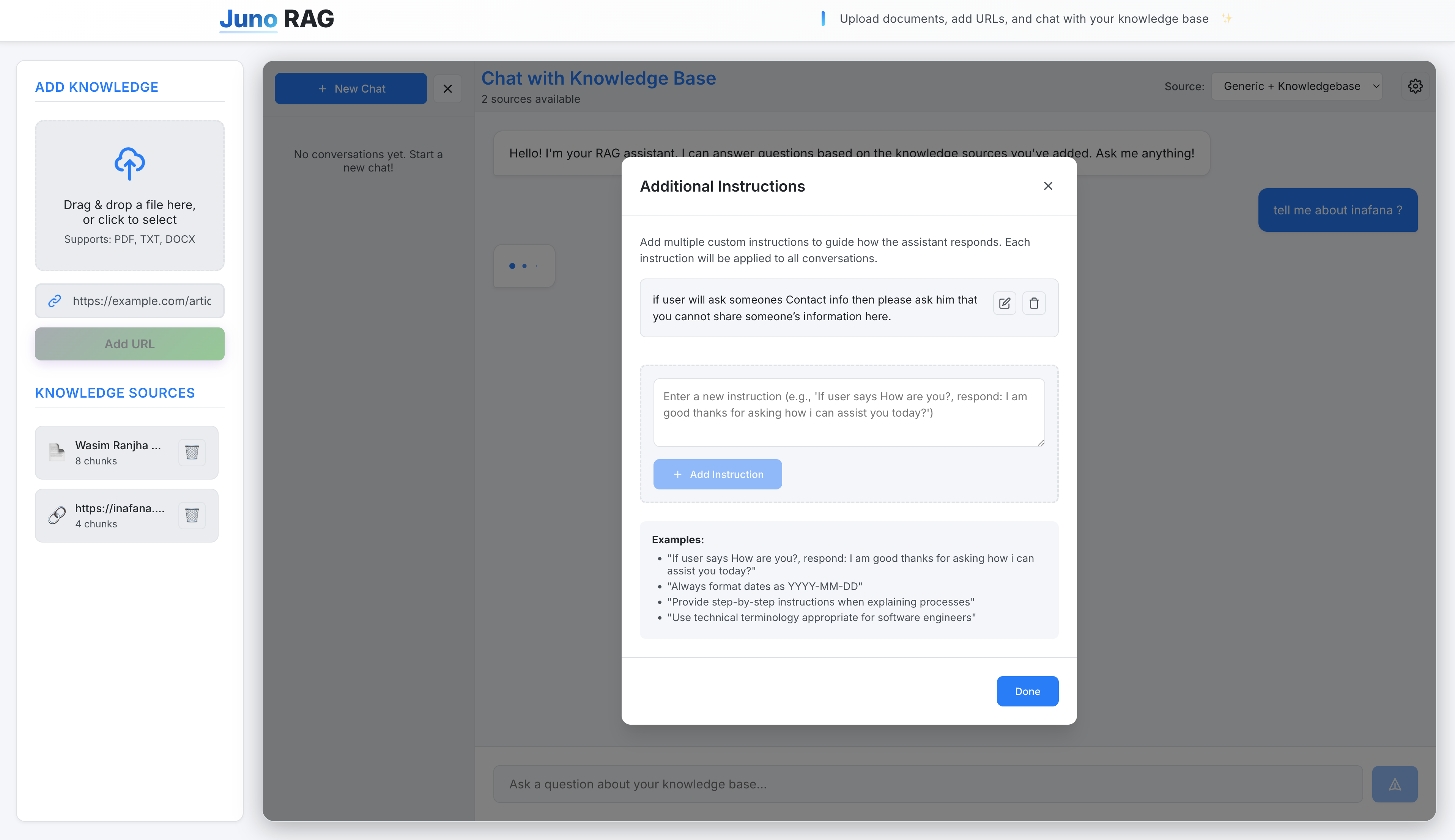
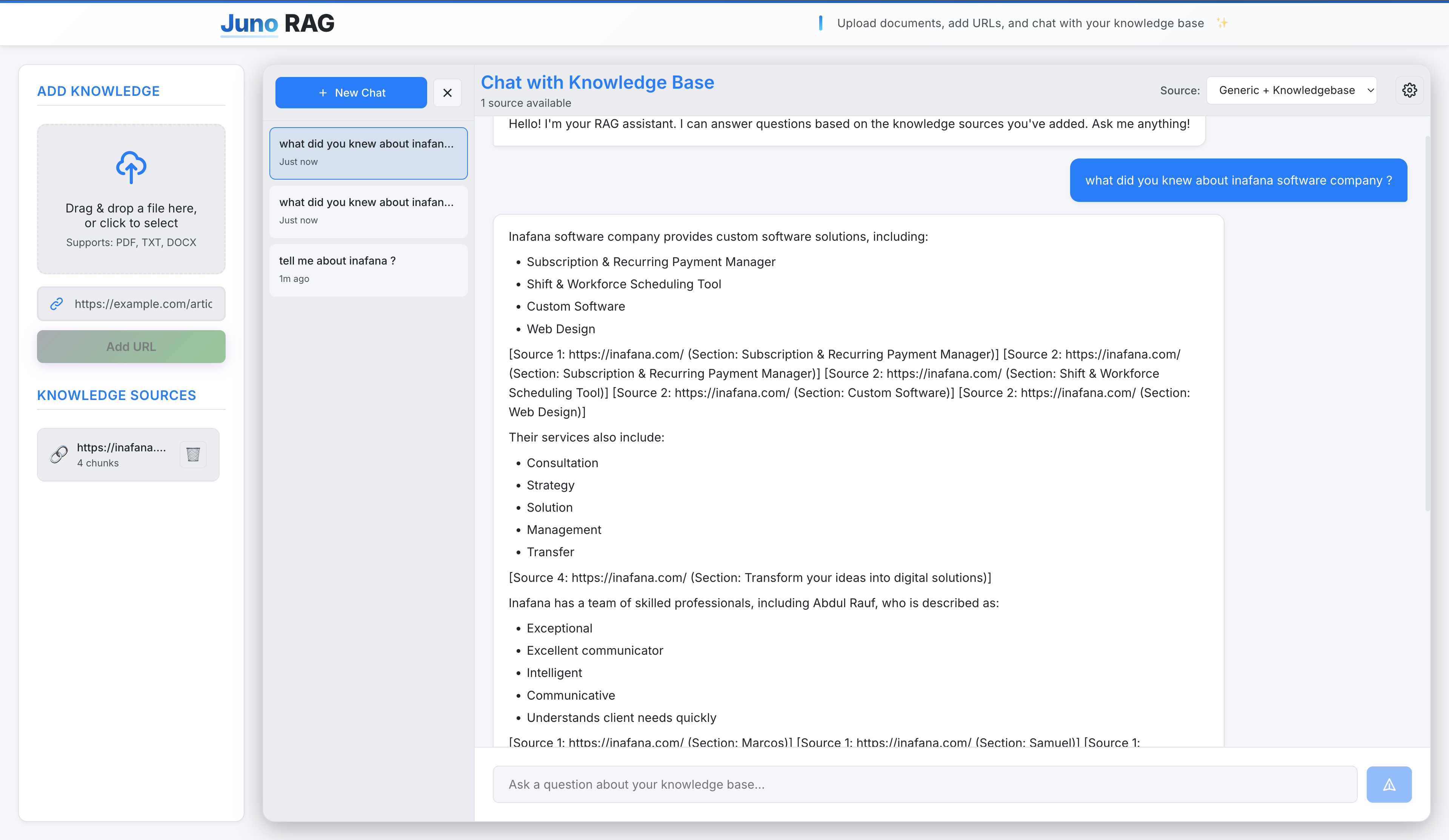
Juno RAG is a production-ready Retrieval-Augmented Generation platform that enables users to build intelligent knowledge bases from their own documents and web content. The system combines cutting-edge AI technologies with a modern, user-friendly interface to deliver accurate, context-aware responses based on custom knowledge sources.
KEY FEATURES
- Multi-Format Document Processing - Supports PDF, TXT, and DOCX files with advanced text extraction including OCR capabilities for scanned documents
- Web Content Integration - Extract and index content from web URLs, making web articles and documentation searchable
- Hybrid Search Technology - Combines semantic search (understanding meaning) with keyword search (BM25) for comprehensive document retrieval
- Intelligent Re-Ranking - Uses cross-encoder models to re-evaluate and re-order search results for maximum relevance
- Conversation Memory - Maintains conversation history and context across multiple interactions for more natural dialogue
- Multi-Tenant Architecture - Secure session-based user isolation ensuring data privacy and security
- Source Citation - Every response includes references to the source documents used, ensuring transparency and verifiability
- Confidence Scoring - Provides confidence metrics for each response, helping users understand answer reliability
The platform features a modern React frontend with a beautiful dark-themed UI, drag-and-drop file uploads, and real-time chat interface. The FastAPI backend is optimized for production use with advanced prompt engineering, query expansion, and multi-provider LLM support (OpenAI, Anthropic, Groq).
TECHNICAL ARCHITECTURE
The system uses ChromaDB as a persistent vector database, storing document embeddings locally for fast semantic search. Documents are intelligently chunked with overlap to maintain context, and each chunk is converted into high-dimensional vectors using SentenceTransformers models. When users ask questions, the system performs hybrid search to find relevant chunks, re-ranks them for accuracy, and sends the top results to the LLM for context-grounded answer generation.
Advanced features include query analysis and expansion for complex questions, source pre-filtering to eliminate irrelevant content, and support for multiple knowledge source modes (knowledgebase-only or generic+knowledgebase). The platform is designed with security in mind, using backend-controlled session management and user isolation at the database level.